闲鱼爬虫秒拍:如何高效抓取闲鱼商品信息
在二手交易市场中,闲鱼无疑是最受欢迎的平台之一。通过闲鱼,用户可以轻松地买卖各类商品。然而,对于一些开发者或数据分析师来说,如何高效地抓取闲鱼商品信息,成为了一个重要课题。本文将围绕这一问题展开讨论,提出可能遇到的问题,并提供解决方案,帮助大家更好地理解闲鱼爬虫的工作原理。
问题一:为何需要抓取闲鱼商品信息?
抓取闲鱼商品信息的需求主要来源于以下几点:
· 市场分析:通过分析闲鱼上的商品信息,商家可以更好地了解市场趋势,把握用户需求。
· 价格监控:抓取商品价格变化,帮助用户或商家进行价格定位和调整。
· 竞争对手分析:了解竞争对手在闲鱼上的产品和价格策略,制定相应的竞争策略。
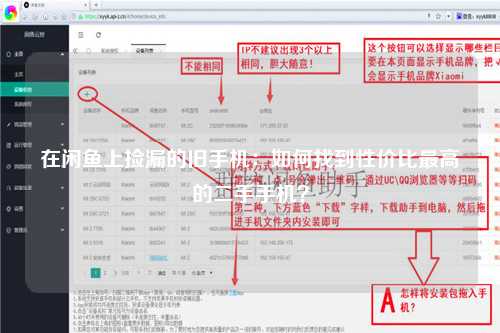
问题二:闲鱼的反爬虫机制如何?
闲鱼作为一个大型的二手交易平台,自然会有一些反爬虫机制来保护平台的数据安全。常见的反爬虫手段包括:
· IP限制:对短时间内大量请求的IP进行封禁。
· 验证码:请求频率过快时,系统可能会要求用户输入验证码。
· 动态内容加载:许多商品信息通过JavaScript动态加载,直接抓取HTML文档可能无法得到完整信息。
因此,在抓取闲鱼数据时,需要采取一定的策略来绕过这些反爬虫机制。
问题三:如何设计有效的爬虫策略?
在面对反爬虫机制时,合理的爬虫策略显得尤为重要。以下是一些有效的抓取策略:
· 合理设置请求间隔:避免短时间内发送大量请求,可以设置随机的请求间隔,以模拟人类用户的行为。
· 使用代理IP:通过代理服务器发送请求,避免因某一IP地址请求过于频繁而导致封禁。
· 模拟用户行为:使用浏览器自动化工具(如Selenium)模拟用户的点击、滚动等操作,抓取动态加载的内容。
问题四:使用哪些工具和技术进行抓取?
在进行闲鱼商品信息抓取时,可以使用以下工具和技术:
· Python:Python语言因其简单易用和丰富的库,成为抓取工作的首选语言。
· Beautiful Soup:用于解析HTML和XML文档,提取数据的强大工具。
· Scrapy:一个快速高效的爬虫框架,适合大规模数据抓取。
· requests库:用于发送HTTP请求,获取网页内容。
· Selenium:用于模拟浏览器行为,抓取动态网页内容。
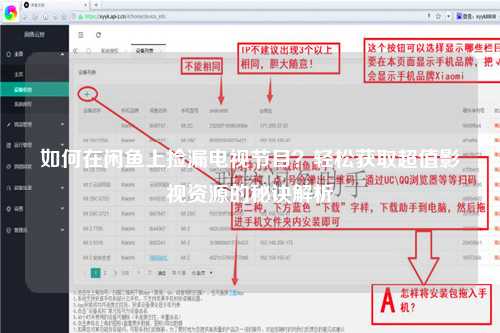
问题五:如何处理抓取到的数据?
抓取数据后,如何进行有效的处理和分析是另一个重要问题。以下是一些常见的数据处理步骤:
· 数据清洗:去除重复数据、空值和无用信息,以提高数据质量。
· 数据存储:可将清洗好的数据存储到数据库(如MySQL、MongoDB)中,便于后续查询和分析。
· 数据分析:使用数据分析工具(如Pandas、Matplotlib)对抓取的数据进行分析,提取有价值的信息。
问题六:如何确保抓取的合法性?
在进行数据抓取时,合法性是一个重要的考虑因素。建议遵守以下原则:
· 遵循robots.txt文件:查看闲鱼的robots.txt文件,了解允许和禁止爬取的内容。
· 不要过于频繁请求:设置合理的请求频率,避免影响网站的正常运行。
· 使用合法的API:如果闲鱼提供开放API,尽量通过API获取数据,而非直接抓取网页。
问题七:常见问题与解决方案
在抓取过程中,可能会遇到一些常见的问题,以下是一些解决方案:
· 请求被拒绝:可能是因为IP被封禁,可以尝试更换IP或使用代理。
· 数据格式不规范:抓取到的数据可能存在格式不一致的问题,需进行数据清洗和格式化。
· 动态内容无法抓取:使用Selenium等工具模拟浏览器行为,等待页面加载完成后再进行数据提取。
总结
抓取闲鱼商品信息虽然充满挑战,但通过合理的策略和工具,可以高效地完成任务。遵循合法性原则,尊重数据的所有权,才能在数据抓取的过程中,获取有价值的信息。希望本文能够为您在进行闲鱼爬虫时提供一些启示和帮助。

微信号:pps688888
添加微信好友, 获取更多信息
复制微信号